Metaprompting is a skill everyone who uses AI needs to master in 2026
Most people use AI like a fancier search engine. Here’s the technique that compounds with every version.
Source: x.com
Source: x.com
TL;DR
My YouTube prompt is on version 27. It got there through meta-prompting, a technique that turns your inputs and outputs into a compounding system. A 72B model with one meta prompt beat GPT-4.
My YouTube prompt is on v27.
Not twenty-seven conversations with ChatGPT. Twenty-seven deliberate cycles of running output, critiquing it, refining the instruction, and making the next run smarter. That’s not prompting. That’s engineering.
Most people type a question into an AI, get an answer, and move on. Version 1, forever. Mitchell Hashimoto calls this “blind prompting”: crude trial-and-error with no systematic testing, no feedback loop, no versioning. He found the same prompt on a more powerful model can produce worse results. Not the same. Worse.
My YC partners Jared Friedman, who built Scribd, and Pete Koomen, who built Optimizely, showed me the way out. They call it meta-prompting: using an LLM to generate, refine, and improve the very prompts you use to get work done.
How the Loop Works
Start with something you do all the time. Your actual inputs and outputs. Drop them into a context window and tell the AI: “Write me a prompt that can act as an agent that takes this input and makes this output.” You can even ask it to introspect: “What are things you notice that I did to convert this from the input to the output?”
That gives you v1. It’s going to suck, because the AI doesn’t know your preferences yet. It doesn’t know your voice, your shortcuts, the things you’d never say.
So you talk to it like a direct collaborator. “I would never say that.” “Use the short word, not the long one.” “Don’t structure it that way.” Direct, conversational, specific. When the output finally sounds right, fold everything back: “Based on this conversation, give me a better initial prompt that incorporates all the things we talked about.”
That’s v2. Run it again. Critique again. Refine again.
I do this with everything. Tweets. Podcast outlines. YouTube scripts. I have a folder of prompts I use every day, each one shaped through this exact cycle. On the YC Lightcone podcast we went into detail, even walking through a few real prompt examples from our top startups:
One special way to approach it is a model tournament. I run the same prompt through GPT 5.2 Pro, Grok Heavy, Gemini Pro, and Claude Opus. I put all the outputs into Claude and ask: “Rate each response. Tell me the pros and cons. Give it to me in numbered form.” Agree with one. Disagree with two. Add nuance to three. Then: “Given all of this, synthesize.”
The point isn’t Claude. The point is that human curation makes the loop work. One study on agent skill generation found that curated skills improved agent pass rates by 16.2 percentage points, while self-generated skills produced zero benefit. Zero. The curation is everything.
Most AI Apps Are Horseless Carriages
Pete Koomen wrote an essay that should be required reading for anyone building with AI. His argument: most AI apps today are “horseless carriages.” They bolt AI onto old software patterns instead of redesigning for what AI can actually do.
Gmail’s Gemini draft feature is his prime exhibit. Type a prompt asking it to email your boss about being sick. It returns “Dear Garry, I am writing to inform you…” in a tone so stiff it reads like a phishing attempt. What Pete would actually write: “Hey garry, my daughter woke up with the flu so I won’t make it in today.” The prompt was longer than the email.
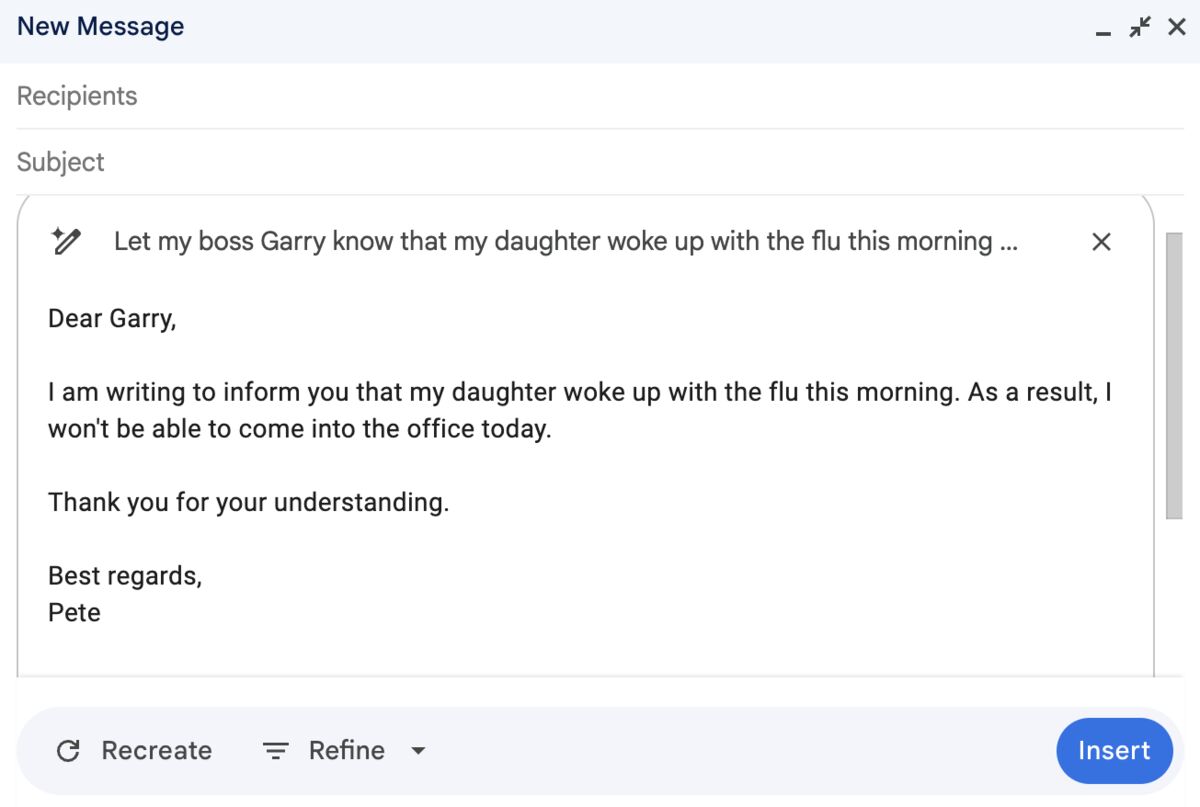
The fix isn’t smarter models. Gemini is powerful enough already. The fix is letting users write their own system prompts. Pete created a “Pete System Prompt” describing his writing style once, and every future email sounded like him: “Garry, my daughter has the flu. I can’t come in today.” Done.
His conclusion: most AI apps should be agent builders, not agents. Build interfaces for creating and iterating on prompts. Stop hiding the system prompt behind a one-size-fits-all wall.
The real power of meta-prompting is upstream of the AI. Before you can teach a model how you think, you have to figure out how you think. A journalist knows how to write a lede, but could they describe the specific pattern they use, precisely enough that a machine could replicate it? A great podcast editor knows how to pace a conversation, but could they write down the rules?
This is the first time ordinary people can program computers in their own language. Not code. Plain conversational feedback. “I would never say that. Use the short word.” Every correction forces you to articulate a preference you never had to name before. By v27, you’ve mapped your own thinking more precisely than most people ever do.
Meta-prompting is A/B testing for AI instructions. Pete co-founded Optimizely, the company that brought A/B testing to the web. Same discipline. Same principle. New medium.
The Math Is Real
This isn’t vibes. Meta-prompting has hard research behind it.
Zhang et al. showed that a Qwen-72B model guided by a single meta prompt hit 46.3% on the MATH benchmark and 83.5% on GSM8K. GPT-4’s initial MATH score was 42.5%. A 72-billion parameter model with better instructions beat GPT-4. The prompt was the product.
Few-shot prompting gives the LLM examples of WHAT you want. Meta-prompting gives it a framework for HOW to think. That shift from content to structure is what makes the technique compound.
Then there’s the genuinely weird finding. Researchers discovered that pruning prompts into grammatically broken “gibberish” can improve performance. “Let’s work this out step by step to be sure we have the right answer” scores 81.5%. “Let’s work out step by step sure we right answer” scores 86.7%. The broken version won. LLMs don’t think in English. They think in patterns.
This is why versioning matters. The best prompt for a human to read and the best prompt for a model to execute may be different prompts entirely. Iterating toward what works, not what reads well, is part of what separates v27 from v1.
What About Model Drifting?
If models improve rapidly, don’t optimized prompts become worthless? The concern is real. PromptBridge formally identified “Model Drifting”: reusing a prompt across models often yields substantially worse performance. Mitchell Hashimoto found the same: “the same prompt even on a more powerful model is not guaranteed to have the same or better accuracy; the accuracy can go down.”
But my multi-model tournament is a built-in hedge. I’m not optimizing for GPT-5.2. I’m synthesizing across architectures. When a new model comes out and it performs poorly, go from v27 to v28. Iterate a few more times. You’re golden again.
And the meta-prompt, the process that generates your working prompt, transfers even when the output prompt needs updating. You rebuild v28 faster because v27 taught you what matters. The knowledge compounds even if the individual prompt doesn’t.
From Flywheel to Factory
What I do manually is the human version of what automated systems already do at scale. DSPy from Stanford automates the entire loop programmatically. In a multi-use case study, accuracy jumped from 46.2% to 64.0%. Same feedback loop: generate candidate prompts, evaluate against metrics, iterate.
The future isn’t everyone hand-crafting v27. It’s AI apps that help you build and iterate your own prompts. Prompt versioning is becoming real engineering infrastructure, with version control, rollback, and A/B testing built in. Pete’s prediction: system prompts should be written and maintained by users, not developers. Agent builders, not agents.
The Prompt Is the Craft
A musician refines their setlist over hundreds of shows, cutting what doesn’t land, extending what does, finding the order that makes audiences feel something. Hemingway rewrote the ending to A Farewell to Arms 39 times. Version 27 of a YouTube prompt isn’t obsession. It’s the same practice, applied to a different craft, with a faster feedback loop than either of those examples ever had.
Your first prompts are going to suck. That’s the deal. But each iteration teaches you something about the AI and something about yourself. What do you actually care about in your output? What patterns define your voice? What shortcuts do you take that you never noticed? By v10, you’re dangerous. By v20, you wonder how you ever worked without this.
The people who treat their prompts like software, versioned, iterated, continuously improved, are building something that compounds. Everyone else is still asking Google with extra steps.
Open a new file. Drop in your last ten outputs. Ask the AI to write you a prompt. That’s v1.
Related Links
-
AI Horseless Carriages by Pete Koomen (koomen.dev)
-
Garry Tan on The Peel Podcast: Meta-Prompting Explained (@ThePeelPod)
-
YC Lightcone: State-Of-The-Art Prompting For AI Agents (Y Combinator)
-
Prompt Engineering vs Blind Prompting (Mitchell Hashimoto)
-
Meta-Prompting: LLMs Crafting Their Own Prompts (IntuitionLabs)
-
What is Prompt Versioning? (Braintrust)
Comments (0)
Sign in to join the conversation.