GPT-5.4 Cracked a 20-Year Math Problem
A Polish mathematician spent two decades building a research-level problem no AI could touch. Run 11 proved him wrong.

TL;DR
A Polish mathematician who publicly called AI “a very advanced calculator” in July 2025 just watched GPT-5.4 solve a research problem he spent 20 years crafting. Only 1 of 11 attempts succeeded, but that was enough to change his mind completely.
Eight months ago, Bartosz Naskręcki was on record: AI was nothing more than a very advanced calculator. It could crunch numbers, but it didn’t understand deep mathematics. True mathematical reasoning, he said, requires “creativity, intuition and the ability to connect seemingly unrelated concepts, something that machines are still unable to do.”
This week, he called GPT-5.4 his personal “Move 37.”
It finally happened-my personal move 37 or more. I am deeply impressed. The solution is very nice, clean, and feels almost human. While testing new models in the last few weeks, I felt this coming, but it's an eerie feeling to see an algorithm solve a task one has curated for about 20 years. But at least I have gained a tool that understands my idea on par with the top experts in the field. And I am now working on a completely new level. My singularity has just happened… and there is life on the other side, off to infinity!
The Man Who Built the Test to Prove AI Couldn’t Reason
Naskręcki isn’t a pundit. He’s Vice-Dean of the Faculty of Mathematics and Computer Science at Adam Mickiewicz University in Poznan, a researcher at the Centre for Credible AI in Warsaw, and one of only five European mathematicians invited to contribute problems to FrontierMath, the hardest AI math benchmark ever built. He co-authored problems with Ken Ono, one of the world’s leading number theorists, and Ravi Vakil, president of the American Mathematical Society.
His FrontierMath Tier 4 problem was a career compressed into a single question. He spent 20 years building the mathematical knowledge base for it, drawing on Galois theory, algebraic geometry, and arithmetic. He originally proved the specific result in an unpublished paper about eight years ago, then deliberately “spiced it up” before submission to make it as hard as possible. He then pre-tested it against o4-mini-high, specifically to make sure current models couldn’t touch it. He designed stumbling blocks on purpose.
Think of it like a master locksmith who spent two decades crafting a lock, then spent months adding extra tumblers after watching the best lockpick in the world fail to open it. The problem wasn’t just hard. It was engineered to be unsolvable.
Then GPT-5.4 did it “smoothly, methodically.”
11 Tries, One Breakthrough
Epoch AI ran GPT-5.4 (xhigh) on Naskręcki’s problem eleven independent times. Only one succeeded. The first ten each explored a slightly different approach, and none of them reached the critical insight that unlocked the solution. That’s the honest version of what happened: 10 failures, 1 success, on a problem designed to stop current AI cold.
Archived tweetWe ran GPT-5.4 (xhigh) an additional ten times on Tier 4 to get a pass@10 score. This was 38%. In one of these runs, it solved another problem no model had solved before. This problem was by @nasqret. https://t.co/34A1saoqN6
Epoch AI @EpochAIResearch March 05, 2026
Naskręcki published a formal analysis of all eleven runs titled “Performance Analysis of Repeated LLM Attempts at a Research-Level Mathematics Problem.” His own subtitle for the paper: “a striking illustration of the last-mile problem in AI mathematical reasoning.” He estimates the total compute for all 11 runs was somewhere between 5 and 15 million tokens with reasoning, which translates to a sustained multi-hour computational effort. This wasn’t a quick lookup. It was the equivalent of a very long research session.
What run 11 found was not brute force. The model identified a “very nice pattern for the relation between arithmetic and the geometry of the problem.” It used what Naskręcki described as “one very nice summation trick” to extrapolate a solution path that let it avoid needing the most advanced mathematical machinery. He was explicit that this was legitimate mathematics, not a shortcut in the pejorative sense. “This isn’t a bad hack,” he said. “I find the overall solution very impressive.”
The 1/11 success rate matters. It tells you this is the fragile frontier of what AI can do, not a reliable capability it can call on demand. But “early birds,” as Naskręcki put it, tend to indicate a qualitative shift that becomes consistent in subsequent model generations. What’s rare today becomes standard tomorrow.
From Under 2% to 50% in Sixteen Months
The single solve would be notable in isolation. In context, it’s one data point in one of the steepest capability curves ever documented on a research benchmark.
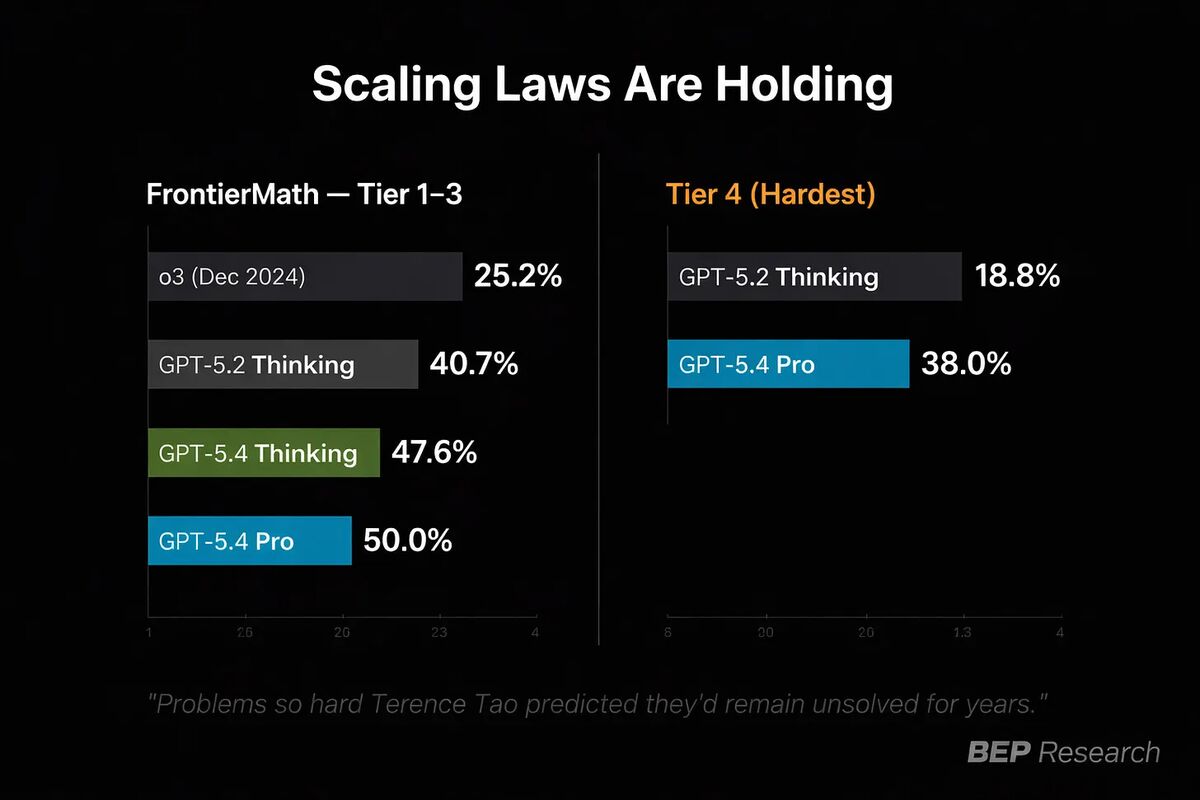
When FrontierMath launched in late 2024, the best AI models solved under 2% of the hardest problems. Terence Tao, widely considered the world’s greatest living mathematician, called the problems “incredibly difficult” and predicted they’d remain beyond AI’s reach for years. Igor Pak suggested some might resist AI for up to 50 years.
The progression since then: o3 in December 2024 scored 25.2% on Tiers 1-3. GPT-5.2 Thinking hit 40.7%. GPT-5.4 Pro reached 50%. On Tier 4, the hardest research-level problems: GPT-5.2 scored 18.8%. GPT-5.4 Pro scored 38%, a near-doubling in months. Across all model runs ever, 42% of the 48 Tier 4 problems have now been solved at least once. That number was essentially zero at launch.
One important caveat, because intellectual honesty matters here: GPT-5.4 Pro was also evaluated on FrontierMath: Open Problems, a set of genuinely unsolved research mathematics that has resisted serious attempts by professional mathematicians. It solved zero. It made some novel observations on one problem, but the problem author characterized them as “relatively uninteresting.” The next frontier is still intact. What’s falling is the tier of problems that PhD specialists need at least a month to understand how to approach. What’s not falling yet is the tier that nobody has solved at all.
The Conflict of Interest You Should Know About
FrontierMath was funded by OpenAI, which has exclusive access to all 290 Tier 1-3 problems, solutions to 237 of them, 28 of the 48 Tier 4 problems, and solutions to those 28. Epoch AI holds out the rest. That’s a structural conflict of interest, and you should factor it in.
The contamination check is somewhat reassuring but imperfect. On Tier 4, GPT-5.4 Pro solved 25% of the non-held-out problems it had access to, and 55% of the held-out problems it had no access to. The difference isn’t statistically significant, but it’s also counterintuitive in the direction that suggests access doesn’t explain the performance. Naskręcki’s specific problem was in the Epoch-held set, meaning OpenAI couldn’t have trained against its solution.
There’s another angle worth noting. A separate Tier 4 problem was solved by GPT-5.4 finding a 2011 preprint the problem’s own author didn’t know existed. The model did novel literature archaeology and found a shortcut the human who wrote the problem had never encountered in years of working on it. That’s not contamination. That’s a different kind of capability, one that should make researchers take stock of what else might be buried in the literature that AI will surface before humans do.
The real signal isn’t statistical. It’s human. A domain expert with 20 years of specific expertise, who publicly staked his reputation on AI being incapable of deep mathematical reasoning, reversed his position completely, without equivocation, after watching the machine work.
Two Singularities: One Headline, One Lab Result
On January 4, 2026, Elon Musk posted “We have entered the Singularity” on X, responding to an engineer’s story about coding productivity over the holidays. Hours later: “2026 is the year of the Singularity.” A million views. No specific scientific result. No definition of what threshold had been crossed.
Musk’s claim was dramatic but diffuse. He was responding to productivity anecdotes. No benchmark. No domain. No criterion for what “entering” the Singularity even meant.
Naskręcki’s version is categorically different. He named the problem. Named the model. Published a formal 11-run analysis. Named the mathematical field. Described the specific technique the model used. And he did all of this as someone who had built his professional reputation on the opposite conclusion.
The Move 37 parallel is worth unpacking. When AlphaGo played Move 37 against Lee Sedol in March 2016, the move wasn’t impressive because AlphaGo won the game. It was impressive because the move itself expanded human understanding of Go. Professional players studied it, not as a curiosity but as a genuine strategic insight that changed how the game was played at the highest levels. Naskręcki is making the same claim about GPT-5.4’s approach: not that it won, but that it found something mathematically interesting and legitimate that he finds genuinely impressive as a professional.
Musk’s singularity is a billboard. Naskręcki’s is a lab result. And lab results are what actually change the world.
Not Displaced. Amplified.
What Naskręcki said after the solve is as important as the solve itself. He didn’t retreat into caveats or qualification. He said: “I feel amazing working now with those models on par but being the leader of ideas.”
The same day GPT-5.4 solved his Tier 4 problem, he used it to find a critical flaw in another idea he’d been developing. The model spotted a counterexample that would have taken him months to discover on his own. He described colleagues at his faculty exchanging tricks for using Codex and Claude in research and teaching: “it’s really starting to take off nicely.”
This is the pattern emerging across domains. The professionals engaging most seriously with frontier AI models report not displacement but transformation. The work shifts from execution toward problem formulation, evaluation, and the generation of novel ideas the models can’t yet produce independently. Naskręcki had predicted exactly this in earlier interviews, when he argued that “the last domain left for mathematicians will be coming up with new, crazy mathematical ideas.” The difference now is that he’s living inside that transition rather than theorizing about it from a comfortable distance.
Upon popular request, I want to give a high-level overview of the 11 attempts the OpenAI model made during the iterations run at EpochAI while trying to solve my FrontierMath Tier 4 question. Unfortunately, we cannot share the details of any of the solutions, nor can we say anything about the problem itself. It is still being used for validation of current models and will remain in the benchmark among the other 47 undisclosed problems that were submitted in May last year. What I find quite striking is that the model explored a slightly different tactic in each run, but only in one run did it reach a critical conclusion that enabled the entire solution. This shows how fragile the reasoning of LLMs still is, and that a solution to a highly complicated problem might indicate merely the frontier of current progress, not a core capability of every run of the model. In my experience, such "early birds" indicate a radical change in quality that will occur in the coming iterations. Also, the model usually has no direct access to the literature or the knowledge of the human challenger. On the other hand, the algorithm can use all its weights, has access to the internet, and can build tools. This is important for making the runs successful. As I said before, I am very pleased with the overall solution (run 11). It is good mathematics written in a nice way. Of course, to make it truly readable one has to convert it into a more human-friendly LaTeX format and compile it into a PDF file, but still-it is ultimately the work of the machine. In the next post, I will write more about the field of mathematics I am most interested in and what kinds of qualities are generally needed to deal with such questions. That might give readers a sense of the overall difficulty of this type of task and why I think the current model's capacity,particularly GPT-5.4, is so impressive. While this remains true for some problems, there is still a huge pool of questions and ideas that remain out of reach for current models. We do not know how things will scale, but the current progress goes far beyond my expectations from last year. The document was generated as a semi-automatic summary and is intended to be read as a very basic overview of the actual run data. Feel free to leave your comments. Thanks!

It finally happened-my personal move 37 or more. I am deeply impressed. The solution is very nice, clean, and feels almost human. …
Three days after GPT-5.4’s FrontierMath record, Andrej Karpathy open-sourced “Autoresearch,” a tool that lets AI agents run autonomous machine learning experiments on single GPUs. The singularity isn’t arriving as one event. It’s arriving domain by domain, researcher by researcher, each one marking the moment where the machine reaches peer level and the human finds out there’s more room to run than they thought.
About a third of the top technical CEOs I know are completely AGI-pilled by coding again. I’m one of them. The question isn’t whether AI will reach expert level across more fields. That’s already happening. The question is what you build with a collaborator that works at expert level, and whether you’re in that conversation now or explaining later why you weren’t.

About 1/3 of the top technical CEOs are completely AGI pilled by coding again. I am one of them. Highly recommend. Totally exhilarating to be back shipping new products and software again
I've been personally burning through billions of tokens a week for the past few months as a builder. Today, I'm excited to announce Hyperagent, by Airtable. …
The mathematician who built the test to prove AI couldn’t reason has now told you, with 20 years of expertise behind him and a 13-page proof to his name, that it can. That’s not hype. That’s data. And the researchers who take it seriously first are the ones who will define what comes next.
Related Links
-
GPT-5.4 set a new record on FrontierMath (Epoch AI)
-
Tough Math Problem Convinces Mathematician the Singularity Is Here (Quantum Zeitgeist)
-
The Reasoning Tax: Why GPT-5.4 Just Validated the Memory Wars (Ben Pouladian)
Comments (3)
Sign in to join the conversation.
While all this is way above my pay grade, what I find interesting is Bartosz Naskręcki’s exhilaration at being undone by AI and not feeling threatened: doors will be opened, not shut. AI noticed a pattern and extrapolated it - a very human activity indeed. I am a fan of neuroscientist and psychiatrist, Dr. Lian McGilchrist. He argues that AI can’t do this. As much as I like his theories on how we’ve siloed human thinking into the left brain hemisphere, his conclusion on AI seemed like wishful thinking, like the cab driver thinking Uber won’t be a thing. I had a college kid ask me what I thought the difference was between AI and humans. I responded that one aspect is our mistakes, or errors, which seem rooted in our humanity. They give way to emotions of sorrow, reconciliation, or, in the materialist realm, scientific breakthroughs. Without errors and mistakes, will we remain human? And for a darker question: will the potential for making errors or mistakes, whether through our emotions or inventions, be prohibited in the future?
While all this is way above my pay grade, what I find interesting is Bartosz Naskręcki’s exhilaration at being undone by AI and not feeling threatened: doors will be opened, not shut. AI noticed a pattern and extrapolated it - a very human activity indeed. I am a fan of neuroscientist and psychiatrist, Dr. Lian McGilchrist. He argues that AI can’t do this. As much as I like his theories on how we’ve siloed human thinking into the left brain hemisphere, his conclusion on AI seemed like wishful thinking, like the cab driver thinking Uber won’t be a thing. I had a college kid ask me what I thought the difference was between AI and humans. I responded that one aspect is our mistakes, or errors, which seem rooted in our humanity. They give way to emotions of sorrow, reconciliation, or, in the materialist realm, scientific breakthroughs. Without errors and mistakes, will we remain human? And for a darker question: will the potential for making errors or mistakes, whether through our emotions or inventions, be prohibited in the future?
Is this what motivated the gstack run? The opportunity to be part of the singularity?